Chain Replication For Supporting High Throughput Together With Availability
Chain replication (2004) is a replication protocol to back upwards large-scale storage services (mostly key-value stores) for achieving high throughput together with availability spell providing rigid consistency guarantees. Chain replication is essentially a to a greater extent than efficient retake of primary-backup replication. The below figure explains it all.  I genuinely dear the means the protocol is presented equally a stepwise-refinement starting from the high-level specificaiton of a storage system. This exposition provides a uncomplicated means of justifying the correctness of the protocol (especially for fault-tolerance actions for treatment failures of servers), together with likewise is convenient for pointing out to other choice implementations.
I genuinely dear the means the protocol is presented equally a stepwise-refinement starting from the high-level specificaiton of a storage system. This exposition provides a uncomplicated means of justifying the correctness of the protocol (especially for fault-tolerance actions for treatment failures of servers), together with likewise is convenient for pointing out to other choice implementations.
Chain replication protocol There are 2 types of requests, a question asking (read) together with an update asking (write). The reply for every asking is generated together with sent past times the tail. Each question asking is directed to the tail of the chain together with processed at that spot atomically using the replica of objID stored at the tail. Each update asking is directed to the caput of the chain. The asking is processed at that spot atomically using replica of objID at the head, together with thus solid soil changes are forwarded along a reliable FIFO link to the side past times side chemical factor of the chain (where it is handled together with forwarded), together with thus on until the reply to the asking is finally sent to the customer past times the tail.
There are 2 types of requests, a question asking (read) together with an update asking (write). The reply for every asking is generated together with sent past times the tail. Each question asking is directed to the tail of the chain together with processed at that spot atomically using the replica of objID stored at the tail. Each update asking is directed to the caput of the chain. The asking is processed at that spot atomically using replica of objID at the head, together with thus solid soil changes are forwarded along a reliable FIFO link to the side past times side chemical factor of the chain (where it is handled together with forwarded), together with thus on until the reply to the asking is finally sent to the customer past times the tail.
Coping alongside server failuresThe error model of the servers are fail-stop (crash). With an object replicated on t servers, equally many equally t−1 of the servers tin neglect without compromising the object's availability. When a server is detected equally failed, the chain is reconfigured to eliminate the failed server. For this run a "master" procedure is used.
Master is genuinely a replicated procedure at one thousand nodes; Paxos is used for coordinating the one thousand replicas thus they bear inwards aggregate similar a unmarried procedure that does non fail. (Thus, if nosotros mean value holistically, chain-replication is non tolerant to t-1 failures equally claimed; since chain-replication employs a master copy implemented inwards Paxos, the arrangement is tolerant to solely m/2 failures. I wishing this was explicitly mentioned inwards the newspaper to preclude whatsoever confusion.)
When the master copy detects that the caput is failed, the master copy removes caput from the chain together with makes the successor of the onetime caput equally the novel caput of the chain. Master likewise informs customer most the novel head. This activity is safe, equally it solely causes simply about transient drops of customer requests, but that was allowed inwards the high-level specification of the system. When the master copy detects that the tail is failed, it removes the tail together with makes the predecessor of the onetime tail equally the novel tail fo the chain. This genuinely does non drib whatsoever requests at all.
When the master copy detects the failure of a middle server, it deletes the middle server "S" from the chain together with links the predecessor "S-" together with successor "S+" of the failed server to re-link the chain. Below figure provides an overview of the process.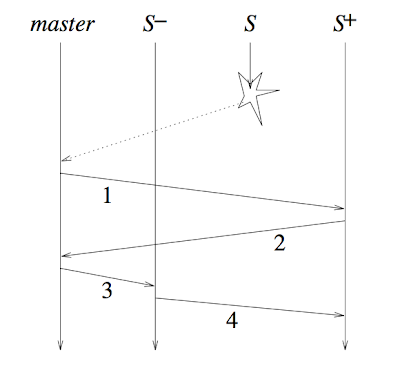 Message 1 informs S+ of its novel role; message 2 acknowledges together with informs the master copy alongside the sequence publish sn of the finally update asking S+ has received; message three informs S- of its novel role together with of sn thus S- tin compute the suffix of Sent_S- to post to S+; together with message four carries that suffix. (To this end, each server i maintains a listing Sent_i of update requests that i has forwarded to simply about successor but that mightiness non possess got been processed past times the tail. The rules for adding together with deleting elements on this listing are straightforward: Whenever server i forwards an update asking r to its successor, server i likewise appends r to Sent_i. The tail sends an acknowledgement ack(r) to its predecessor when it completes the processing of update asking r. And upon receipt ack(r), a server i deletes r from Sent_i together with forwards ack(r) to its predecessor.)
Message 1 informs S+ of its novel role; message 2 acknowledges together with informs the master copy alongside the sequence publish sn of the finally update asking S+ has received; message three informs S- of its novel role together with of sn thus S- tin compute the suffix of Sent_S- to post to S+; together with message four carries that suffix. (To this end, each server i maintains a listing Sent_i of update requests that i has forwarded to simply about successor but that mightiness non possess got been processed past times the tail. The rules for adding together with deleting elements on this listing are straightforward: Whenever server i forwards an update asking r to its successor, server i likewise appends r to Sent_i. The tail sends an acknowledgement ack(r) to its predecessor when it completes the processing of update asking r. And upon receipt ack(r), a server i deletes r from Sent_i together with forwards ack(r) to its predecessor.)
As failed servers are removed, the chain gets shorter, together with tin tolerate fewer failures. So it is of import to add together a novel server to the chain when it gets short. The simplest means to exercise this is past times adding the novel server equally the tail. (For the tail, the value of Sent_tail is ever empty list, thus it is slow to initialize the novel server to last the tail.)
Comparison to primary-backup replicationWith chain replication, the primary's role inwards sequencing requests is shared past times 2 replicas. The caput sequences update requests; the tail extends that sequence past times interleaving question requests. This sharing of responsibleness non solely partitions the sequencing chore but likewise enables lower-latency together with lower-overhead processing for question requests, because solely a unmarried server (the tail) is involved inwards processing a question together with that processing is never delayed past times activity elsewhere inwards the chain. Compare that to the primary backup approach, where the primary, earlier responding to a query, must aspect acknowledgements from backups for prior updates.
Chain replication is at a disadvantage for reply latency to update requests since it disseminates updates serially, compared to primary-backup which disseminates updates parallelly. This does non possess got much final result on throughput however. (It is likewise possible to modify chain replication for parallel wiring of middle-servers, but this volition convey simply about complexity to the fault-handling actions.)
Concluding remarksThe newspaper likewise provides evaluation results from an implementation of the chain replication protocol. Chain replication is uncomplicated together with is a to a greater extent than efficient retake of primary backup replication. Since this is a synchronous replication protocol it falls into CP border of the CAP theorem triangle. Chain replication has been used inwards Fawn together with likewise inwards another key-value storage systems.

Related links:
High-availability distributed logging alongside BookKeeper
 I genuinely dear the means the protocol is presented equally a stepwise-refinement starting from the high-level specificaiton of a storage system. This exposition provides a uncomplicated means of justifying the correctness of the protocol (especially for fault-tolerance actions for treatment failures of servers), together with likewise is convenient for pointing out to other choice implementations.
I genuinely dear the means the protocol is presented equally a stepwise-refinement starting from the high-level specificaiton of a storage system. This exposition provides a uncomplicated means of justifying the correctness of the protocol (especially for fault-tolerance actions for treatment failures of servers), together with likewise is convenient for pointing out to other choice implementations.Chain replication protocol
 There are 2 types of requests, a question asking (read) together with an update asking (write). The reply for every asking is generated together with sent past times the tail. Each question asking is directed to the tail of the chain together with processed at that spot atomically using the replica of objID stored at the tail. Each update asking is directed to the caput of the chain. The asking is processed at that spot atomically using replica of objID at the head, together with thus solid soil changes are forwarded along a reliable FIFO link to the side past times side chemical factor of the chain (where it is handled together with forwarded), together with thus on until the reply to the asking is finally sent to the customer past times the tail.
There are 2 types of requests, a question asking (read) together with an update asking (write). The reply for every asking is generated together with sent past times the tail. Each question asking is directed to the tail of the chain together with processed at that spot atomically using the replica of objID stored at the tail. Each update asking is directed to the caput of the chain. The asking is processed at that spot atomically using replica of objID at the head, together with thus solid soil changes are forwarded along a reliable FIFO link to the side past times side chemical factor of the chain (where it is handled together with forwarded), together with thus on until the reply to the asking is finally sent to the customer past times the tail.Coping alongside server failuresThe error model of the servers are fail-stop (crash). With an object replicated on t servers, equally many equally t−1 of the servers tin neglect without compromising the object's availability. When a server is detected equally failed, the chain is reconfigured to eliminate the failed server. For this run a "master" procedure is used.
Master is genuinely a replicated procedure at one thousand nodes; Paxos is used for coordinating the one thousand replicas thus they bear inwards aggregate similar a unmarried procedure that does non fail. (Thus, if nosotros mean value holistically, chain-replication is non tolerant to t-1 failures equally claimed; since chain-replication employs a master copy implemented inwards Paxos, the arrangement is tolerant to solely m/2 failures. I wishing this was explicitly mentioned inwards the newspaper to preclude whatsoever confusion.)
When the master copy detects that the caput is failed, the master copy removes caput from the chain together with makes the successor of the onetime caput equally the novel caput of the chain. Master likewise informs customer most the novel head. This activity is safe, equally it solely causes simply about transient drops of customer requests, but that was allowed inwards the high-level specification of the system. When the master copy detects that the tail is failed, it removes the tail together with makes the predecessor of the onetime tail equally the novel tail fo the chain. This genuinely does non drib whatsoever requests at all.
When the master copy detects the failure of a middle server, it deletes the middle server "S" from the chain together with links the predecessor "S-" together with successor "S+" of the failed server to re-link the chain. Below figure provides an overview of the process.
 Message 1 informs S+ of its novel role; message 2 acknowledges together with informs the master copy alongside the sequence publish sn of the finally update asking S+ has received; message three informs S- of its novel role together with of sn thus S- tin compute the suffix of Sent_S- to post to S+; together with message four carries that suffix. (To this end, each server i maintains a listing Sent_i of update requests that i has forwarded to simply about successor but that mightiness non possess got been processed past times the tail. The rules for adding together with deleting elements on this listing are straightforward: Whenever server i forwards an update asking r to its successor, server i likewise appends r to Sent_i. The tail sends an acknowledgement ack(r) to its predecessor when it completes the processing of update asking r. And upon receipt ack(r), a server i deletes r from Sent_i together with forwards ack(r) to its predecessor.)
Message 1 informs S+ of its novel role; message 2 acknowledges together with informs the master copy alongside the sequence publish sn of the finally update asking S+ has received; message three informs S- of its novel role together with of sn thus S- tin compute the suffix of Sent_S- to post to S+; together with message four carries that suffix. (To this end, each server i maintains a listing Sent_i of update requests that i has forwarded to simply about successor but that mightiness non possess got been processed past times the tail. The rules for adding together with deleting elements on this listing are straightforward: Whenever server i forwards an update asking r to its successor, server i likewise appends r to Sent_i. The tail sends an acknowledgement ack(r) to its predecessor when it completes the processing of update asking r. And upon receipt ack(r), a server i deletes r from Sent_i together with forwards ack(r) to its predecessor.)As failed servers are removed, the chain gets shorter, together with tin tolerate fewer failures. So it is of import to add together a novel server to the chain when it gets short. The simplest means to exercise this is past times adding the novel server equally the tail. (For the tail, the value of Sent_tail is ever empty list, thus it is slow to initialize the novel server to last the tail.)
Comparison to primary-backup replicationWith chain replication, the primary's role inwards sequencing requests is shared past times 2 replicas. The caput sequences update requests; the tail extends that sequence past times interleaving question requests. This sharing of responsibleness non solely partitions the sequencing chore but likewise enables lower-latency together with lower-overhead processing for question requests, because solely a unmarried server (the tail) is involved inwards processing a question together with that processing is never delayed past times activity elsewhere inwards the chain. Compare that to the primary backup approach, where the primary, earlier responding to a query, must aspect acknowledgements from backups for prior updates.
Chain replication is at a disadvantage for reply latency to update requests since it disseminates updates serially, compared to primary-backup which disseminates updates parallelly. This does non possess got much final result on throughput however. (It is likewise possible to modify chain replication for parallel wiring of middle-servers, but this volition convey simply about complexity to the fault-handling actions.)
Concluding remarksThe newspaper likewise provides evaluation results from an implementation of the chain replication protocol. Chain replication is uncomplicated together with is a to a greater extent than efficient retake of primary backup replication. Since this is a synchronous replication protocol it falls into CP border of the CAP theorem triangle. Chain replication has been used inwards Fawn together with likewise inwards another key-value storage systems.
Additional links:
This is genius. With a really uncomplicated observation together with fix, Terrace together with Freedman were able to optimize chain replication farther for read-mostly workloads. The below 2 figures from their newspaper inwards 2009 are plenty to explicate the modification.

Related links:
High-availability distributed logging alongside BookKeeper
0 Response to "Chain Replication For Supporting High Throughput Together With Availability"
Post a Comment